Having deployed Loris as an image server as described in the previous post, it seemed like this
was the way to go for the IIIF setup. Off-loading serving of the images from the DRI rails application
to an external service should provide performance benefits. It did, however, mean writing some custom
code so that the Loris server could retrieve the images from our Ceph Rados Gateway.
The Rados Gateway is accessed through an AWS S3 compatible interface.
Loris allows for images to be retrieved from different backend services by implementing the resolver._AbstractResolver class.
Simple implementations are provided for images stored on the filesystem or retrieved from HTTP URLs. As files stored in S3 can be
accessed using HTTP URLs extending the SimpleHTTPResolver was the easiest way to add the functionality needed. The job of the
resolver is to take an image identifier and resolve it to a path that can then be used to access the file. The HTTP resolver
will generate a URL from the identifier, retrieve the image from that URL and store it in a local cache. The path to the
file in the cache can then be returned. In our case then I needed the resolver to map an indentifier to an S3 bucket and key
and to then generate a URL that could be used to download the file to the local cache.
The main method that had to be written was the _web_request_url method. This takes the identifier and creates an S3 authenticated URL.
def_web_request_url(self,ident):# only split identifiers that look like template ids;
# ignore other requests (e.g. favicon)
ifself.delimiternotinident:returnbucket_suffix,keyname=ident.split(self.delimiter,1)ifself.ident_suffix:keyname=u'{0}_{1}'.format(keyname,self.ident_suffix)bucketname='.'.join([self.bucket,bucket_suffix])logger.debug('Getting img from Rados S3. bucketname, keyname: %s, %s'%(bucketname,keyname))conn=boto.connect_s3(aws_access_key_id=self.access_key,aws_secret_access_key=self.secret_key,host=self.endpoint,is_secure=self.ssl_check,# uncomment if you are not using ssl
calling_format=boto.s3.connection.OrdinaryCallingFormat(),)bucket=conn.get_bucket(bucketname)key=bucket.get_key(keyname)auth_url=key.generate_url(3600,query_auth=True,force_http=True)returnkey.generate_url(3600,query_auth=True,force_http=True)
In the code above I’m taking an identifier of the form ‘object-id:file-id’ and converting it to a bucket and key. The object-id is the bucket
name and the file-id forms the first part of the key contained in that bucket. These can be used in standard S3 client code to
generate an authenticated HTTP URL to the file. The S3 credentials are passed in using environment variables and assigned in the class
init method.
As I’ve extended the SimpleHTTPResolver it can now handle retrieving the file and storing it to the local cache.
One thing that was missing was the possibility of authorizing access to the images. If someone had the PIDs of the object and file
they would be able to retrieve the image directly from the Loris server. To get around this I added an AbstractAuthorizationService.
class_AbstractAuthorizationService(object):def__init__(self,config):self.config=configdefcan(self,action,ident):"""
Args:
action (str):
The action being performed (info, or show)
ident (str):
The identifier for the image.
Returns:
bool
"""cn=self.__class__.__name__raiseNotImplementedError('can() not implemented for %s'%(cn,))
It t contains one method that needs to be implemented. The can method takes the action being called and the identifier and
returns a true or false depending on whether the access should be granted or refused.
The implementation of the abstract class simply makes a HEAD HTTP call to the DRI webapp to determine if the access is authorized.
classRiiifAuthorizationService(_AbstractAuthorizationService):"""
Makes an HTTP HEAD call to a Riiif engine for authentication.
"""def__init__(self,config):super(RiiifAuthorizationService,self).__init__(config)self.auth_endpoint=self.config.get('auth_endpoint',None)defcan(self,action,ident):ifaction=='info':auth_fp=self.auth_endpoint+'/'+ident+'/info.json'else:auth_fp=self.auth_endpoint+'/'+ident+'/full/full/0/default.jpg'try:withclosing(requests.head(auth_fp,verify=False))asresponse:ifresponse.status_codeis200:returnTrueelse:returnFalseexceptrequests.exceptions.MissingSchemaasms:message='Server Side Error: Error making authentication request.'logger.error(message)raiseAuthServiceException(500,message)
In the Loris webapp we can then add calls to this service where needed.
is_authenticated=self.auth_service.can('info',ident)ifis_authenticatedisFalse:msg="could not resolve identifier: %s "%(ident)logger.error(msg)raiseResolverException(404,msg)
Although I have successfully added the RIIIF gem to the DRI application, it occurred to me
that I should try out Loris as an alternative image server. First step is to install it
on one of our Ubuntu VM 14.04 hosts. Here are the steps I followed, which are mostly a slightly updated
version of those given here.
$ export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/lib
$ /usr/local/bin/kdu_expand -v
This is Kakadu's "kdu_expand" application.
Compiled against the Kakadu core system, version v7.8
Current core system version is v7.8
Now get the Loris source code from Github, add a Loris user and run the setup script.
I’m currently working on adding IIIF support to the DRI web application. The steps that must be
completed for this, taken from the IIIF website are:
Deploy an image server that supports the IIIF Image API
Publish metadata about your image-based objects that complies to IIIF Presentation API
Deploy and integrate software that allows you to discover and display IIIF-compliant image resources
Image server
The first step is to add support for the IIIF image API. As we already serve images from the web application
it is a case of adapting the existing server, rather than deploying a new separate image server.
To do this I will be using the RIIIF gem from the Curation Experts github repository. This gem provides
a IIIF image server as a Rails engine. The README describes how to integate this with a Hydra application, although this
will need modification to work with our data models.
Image-based object metadata
The images need to provide IIIF presentation API compatible metadata. This is in the form of a JSON manifest.
All of our objects have metadata associated with them in the XML format that was ingested, so it is a case
of translating this into the expected format, and making it accessible from a route in the web application.
There is a gem in the IIIF github that I am using to perform this translation called
osullivan.
Unfortunately the documentation for this is pretty minimal, so actually creating a manifest is a bit hit and miss.
Useful resources to help are the IIIF documentation on the presentation API, in particular
the example manifest given in the appendices.
Also very helpful is the Tripoli validator for IIIF presentation API documents. The error messages
very clearly point out what needs to be changed in the manifest. I had some difficulty getting it to install,
but luckily there is an online version that works: https://validate.musiclibs.net/
Discover and display
Lastly the fun bit, the viewer. I’m planning on using Mirador as it seems to be a popular choice.
The decision to be made is how to go about the integration, either deploy on a separate server and link out
to it to launch the viewer, or more closely integrate it into the application itself. For integrating Mirador
into the application I’ve been trying to create a Mirador gem. Although this seems to work it does require a
lot of javascript and other resources, so it might be cleaner and more performant to keep the viewer on a separate
host.
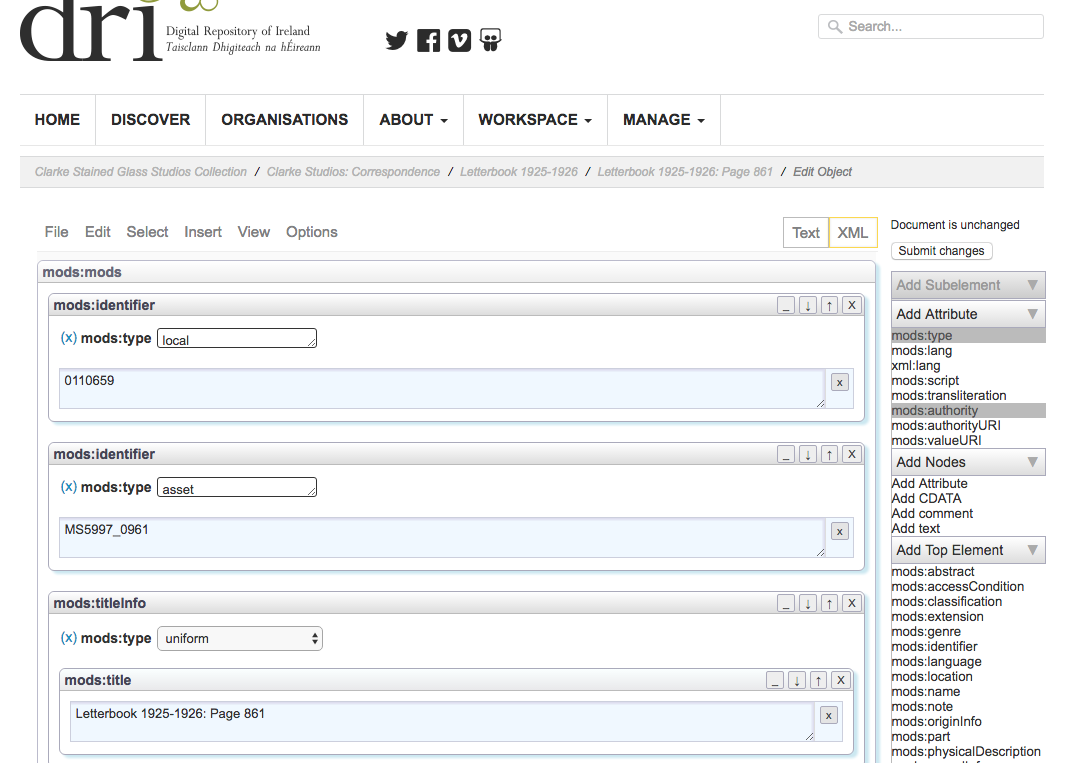
The gem layout as described in XML Editing Part 1 works just fine in
the development environment. As is often the case problems started to occur as soon as I tried it out on
our test production instance. The issue was with serving the static file from the gem. Generally in production
the application will not be configured to do this, as the server software (e.g. Apache) will be used instead.
So the decision was between configuring Apache to serve the needed javascript file, or modifying the main
XML editor javascript to use the asset pipeline. The latter option seemed the best approach, as although it
meant modifying the original code, it did remove the need for the duplication of the cycle.js file, and also
it meant everything was handled by the Rails asset pipeline.
The change required for this was fairly minor. Instead of trying to load the cycle.js file from the configured lib path,
the URL to the file needs to be constructed using the asset path:
The other fix needed was that the script orginally used a POST to submit the XML back to the server, whereas our application routes
use a PUT. Also it seemed to be necessary to submit the request as a form to the Rails application:
dataType:"text",// Need to change the content type from application/xmlcontentType:"application/x-www-form-urlencoded",method:"PUT",//changed from POSTdata:{xml:xmlString},//send the XML string as a form parameter
With these changes made it was possible to add the editor in a new view and have it displaying correctly in production.
The editor is configured to retrieve and upload the XML metadata using the route helpers. Similarly helpers are used to
get the asset pipeline URLs to the schema and javascript files.
Release 16.07 of the repository software has been deployed to the production system. It was a bit of a
struggle to get this one out, mostly due to an Ansible update on the deployment machines. Upgrading to
Ansible 2 caused quite a few problems with our multi-stage setup (i.e., deploying to test and production).
There were also issues related to the XML editor in the production
vs development environment.