One of the main features of DRI is our support for multiple metadata standards. Although user’s can ingest
DC, MARC, MODS and EAD metadata in XML format it has only been possible to edit Dublin Core records. To edit
MARC or MODS required modifying the XML locally and replacing the object metadata with the edited version.
A cataloguing tool that would allow user’s to make these changes in the browser is something that was often
requested. Building web-forms to cater for all these standards has always seemed like too difficult a task.
One possible solution is to enable them to simply edit the XML metadata directly, as they would be doing
locally. This would require adding an XML editor to the Repository UI. The JQuery XML editor
created as part of the Carolina Digital Repository, seemed like it would be exactly what I needed.
To try it out the first step was to gemify it for easier inclusion into the Repository.
First I created a skeleton gem. There are different ways of doing this, but I used bundler.
bundle gem jquery-xmleditor-rails
This creates the basic directory structure for the gem. To this I needed to add the source code for the editor,
which I downloaded from Github. The javascript goes in the app/assets/javascripts directory.
The editor has a number of dependencies, which in Github are stored in the lib directory. I put these
in a vendor directory in the assets javascripts folder, like so:
ls app/assets/javascripts/jquery-xmleditor/vendor/
ace cycle.js jquery.autosize-min.js json2.js
I then created an index.js to load the javascript file and its dependencies when its included into the app.
One problem I ran into was that the javascript tries to load one of the dependencies, cycle.js, from a local
URL. So I needed the gem to make this available. To be honest I’m not sure this is the correct, or best approach,
but to do this I copied the cycle.js file to a public/lib directory. We now need to make the gem serve this file.
This requires modifying some files in the gem’s lib directory.
moduleJQuerymoduleXmlEditormoduleRailsclassEngine<::Rails::Engine# Initializer to combine this engines static assets # with the static assets of the hosting site.initializer"static assets"do|app|app.middleware.insert_before(::ActionDispatch::Static,::ActionDispatch::Static,"#{root}/public")endendendendend
Other than modifying a few more files, such as the version.rb and the gemspec, this was all that was required to create
a functioning gem for the editor. The full code for the gem can be found here.
I’ve been modifying the Repository code to allow for additional storage backends for the surrogates
created from the assets attached to Digital Objects. Currently we use an S3 compatible backend, but would
like the option of simple file storage. Part of this requires serving the surrogate files from the application
rather than re-directing to the S3 URLs.
Serving the files is reasonably straightforward with Rails. Once the path, or URL for the file is retrieved from
the storage backend it can be returned using the send data method. Including the type in the response is important
if you want the file to display inline.
A harder to figure out problem was with the lightbox that we use to display a larger version of the surrogate.
Opening the new surrogate URL in a browser displayed the surrogate inline correctly, however, within the lightbox
the image would display as text. Eventually I found this option in the colorbox documentation:
photo
false
If true, this setting forces Colorbox to display a link as a photo. Use this when automatic photo detection fails (such as using a url like ‘photo.php’ instead of ‘photo.jpg’)
The new URLs did not end in the surrogate filename, so automatic detection was not working. By adding the photo option
to the colorbox initializer the image finally displayed correctly.
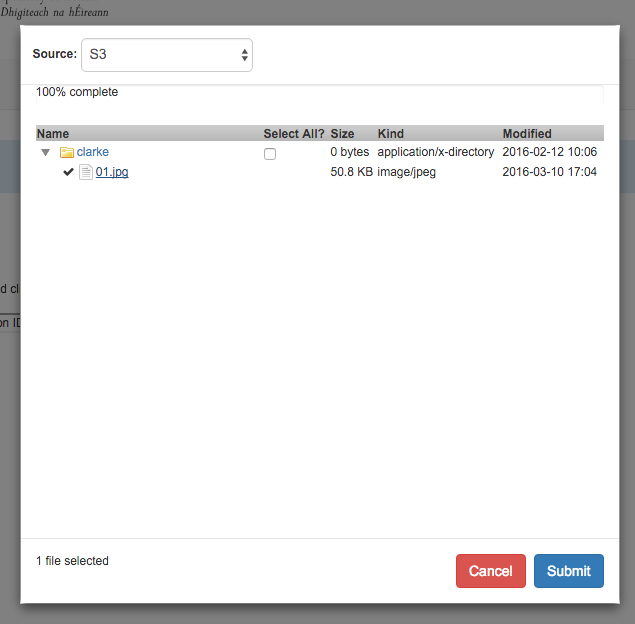
The BrowseEverything gem written by Project Hydra allows for a Rails app to browse and access files in cloud storage. It currently supports Dropbox, Skydrive, Google Drive and Box. I was using it with Dropbox while I was developing a new batch ingest tool for DRI and it worked really well. DRI storage makes use of Ceph with a Rados gateway. The Rados gateway provides an S3 compatible interface on top of Ceph. As this is another cloud storage provider I wondered if it would be possible to add an S3 driver so that I could allow the ingest tool to access files stored in our Ceph storage.
Looking at the existing drivers there was not that many methods that needed to be implemented to make it work.
# validate the configuration retrieved from the config filedefvalidate_config# list the contents of a directorydefcontents(path='')# create a URL for the file that can be used to retrieve the file# from the cloud storagedeflink_for(path)
The first step then was to find a way to convert from buckets and objects to directories and files. Luckily I found a description of how someone had previously done this here. This explains really well how we can use prefix and delimiter to emulate directories and files with S3. I was able to simply re-use the S3::Directory and S3::File classes given in the blog. All this left me to do was to implement the methods above for the S3 driver.
The contents method does the bulk of the work. The client used is an AWS::S3::Client. It’s important to configure it with force_path_style: true rather than DNS style bucket URLs.
defcontents(path='')result=[]unlesspath.empty?result<<BrowseEverything::FileEntry.new(Pathname(path).join('..'),'','..',0,Time.now,true)endifpath==''# if we are in the root list buckets as directoriesresult+=client.list_buckets['buckets'].collectdo|bucket|details(true,bucket.name,0,bucket.creation_date)endelse# if not the root get the parent bucketparts=Pathname(path).each_filename.to_abucket=Aws::S3::Bucket.new(parts[0],client: client)directory=BrowseEverything::Driver::S3Provider::Directory.new(bucket,parts[1..-1].join('/'))# get the details for the subdirectoriesresult+=directory.subdirectories.collectdo|sub|details(true,File.join(bucket.name,sub.path))end# get details for any files in the directoryresult+=directory.files.collectdo|file|object=file.path[:s3_object]full_path=File.join(path,File.basename(object.key))details(false,full_path,object.size.to_i,object.last_modified)endendresultend
When a file is selected we need to convert from a path to an authorized URL. This is done in the auth_link method.
This was a bit more complicated as the Ceph gateway doesn’t support the lastest AWS signature format, so I had to add my own methods to generate the URL rather than using the AWS Client to do it for me. The main other piece of code is the details method which retrieves file size and creation date for the display.
So far it has been working well, although I still need to think about how to do the authentication. Currently the credentials are stored in the BrowseEverything configuration file. It would be good if the user could provide their own keys.
Release 16.01 of the repository software has been tagged and deployed to the production system.
For this release some changes were made to how an object is edited. It should now be easier to manage
the organisations attached to a collection. Also access controls and licences can now be modified
separately from the metadata.
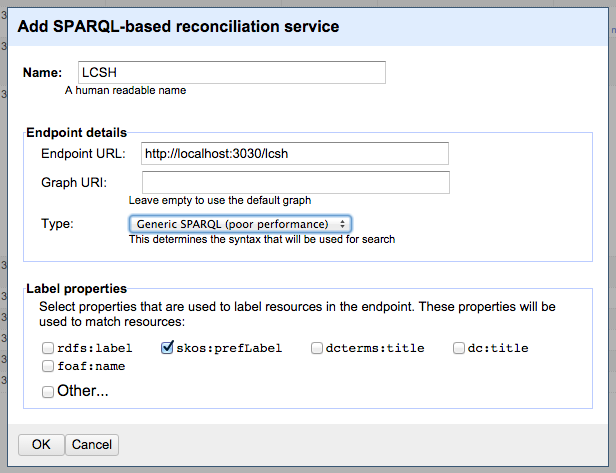
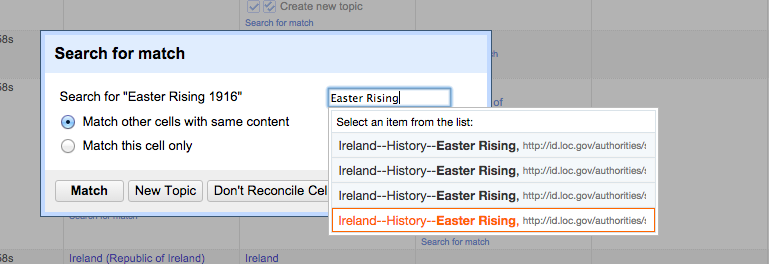
I’ve been looking at creating RDF from the XML metadata of a DRI collection. Part of this involves using OpenRefine to reconcile the metadata with other datasets, mainly dbpedia. I also wanted to add links to LCSH subjects, but was unable to find an available endpoint to use as a reconciliation service. Instead I created a local SPARQL endpoint using Apache Jena Fuseki. The following gives the steps I followed to do this.
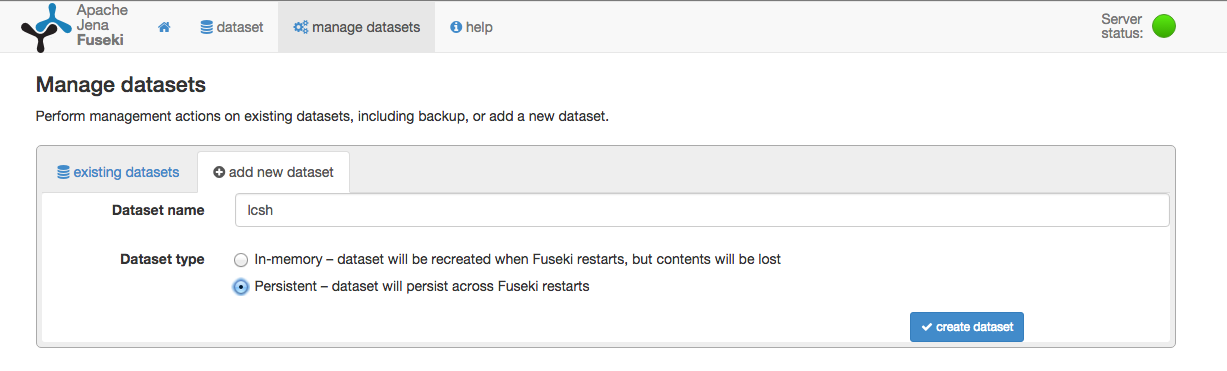
The simplest way I found to create a new dataset is to start the server and use the UI.
./fuseki-server
The server should be available at the default port of 3030 http://localhost:3030. The ‘Manage datasets’ tab allows for a new dataset to be added.
A directory will be created for the new dataset run/databases/lcsh. The next stage is to load the LCSH data.
The LCSH datasets can be found at http://id.loc.gov/download/ in various formats. I used the LC Subject Headings (SKOS/RDF) in RDF/XML, although N-triples should work also. Once downloaded and extracted the dataset can be loaded with the following command: