Linked Data Step 3
19 Aug 2018Linked Data Step 1 was adding RDF, generated from DRI XML metadata, as an output format of the DRI repository application. Step 2 is using OpenRefine to reconcile the RDF metadata fields with other datasets; namely, DBpedia, LCSH (for subjects) and Linked Logainm (for places).
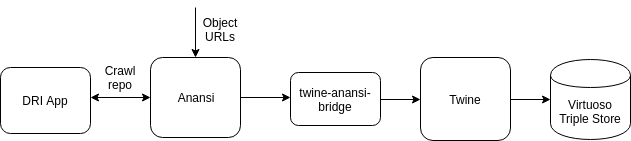
The last step is to import this enhanced RDF, exported from OpenRefine, together with the RDF output generated by the DRI application into a triple store to allow for querying. The final full workflow then, comprised of each of the three steps, is as shown in the figure below.

The RDF generated by the application from the object’s XML metadata follows the guidelines produced by the BBC’s Research and Education Space (RES) Project. To allow for the automation of the process of importing the RDF into the triple store, more components from the RES project can be used. Anansi is a web crawler that ‘includes specific support for Linked Data’. Objects from the repository the we wish to import can be selected by adding their URLs to the Anansi crawl queue. The second component Twine reads resources that have been successfully crawled and processed by Anansi, processes these and imports the resulting RDF to the triple store.
Now on to the fun of SPARQL queries!