BrowseEverything including S3
09 Apr 2016The BrowseEverything gem written by Project Hydra allows for a Rails app to browse and access files in cloud storage. It currently supports Dropbox, Skydrive, Google Drive and Box. I was using it with Dropbox while I was developing a new batch ingest tool for DRI and it worked really well. DRI storage makes use of Ceph with a Rados gateway. The Rados gateway provides an S3 compatible interface on top of Ceph. As this is another cloud storage provider I wondered if it would be possible to add an S3 driver so that I could allow the ingest tool to access files stored in our Ceph storage.
Looking at the existing drivers there was not that many methods that needed to be implemented to make it work.
# validate the configuration retrieved from the config file
def validate_config
# list the contents of a directory
def contents(path='')
# create a URL for the file that can be used to retrieve the file
# from the cloud storage
def link_for(path)The first step then was to find a way to convert from buckets and objects to directories and files. Luckily I found a description of how someone had previously done this here. This explains really well how we can use prefix and delimiter to emulate directories and files with S3. I was able to simply re-use the S3::Directory and S3::File classes given in the blog. All this left me to do was to implement the methods above for the S3 driver.
The contents method does the bulk of the work. The client used is an AWS::S3::Client. It’s important to configure it with force_path_style: true rather than DNS style bucket URLs.
def contents(path='')
result = []
unless path.empty?
result << BrowseEverything::FileEntry.new(
Pathname(path).join('..'),
'', '..', 0, Time.now, true
)
end
if path == ''
# if we are in the root list buckets as directories
result += client.list_buckets['buckets'].collect do |bucket|
details(true, bucket.name, 0, bucket.creation_date)
end
else
# if not the root get the parent bucket
parts = Pathname(path).each_filename.to_a
bucket = Aws::S3::Bucket.new(parts[0], client: client)
directory = BrowseEverything::Driver::S3Provider::Directory.new(
bucket, parts[1..-1].join('/')
)
# get the details for the subdirectories
result += directory.subdirectories.collect do |sub|
details(true, File.join(bucket.name, sub.path))
end
# get details for any files in the directory
result += directory.files.collect do |file|
object = file.path[:s3_object]
full_path = File.join(path, File.basename(object.key))
details(false, full_path,
object.size.to_i, object.last_modified)
end
end
result
endWhen a file is selected we need to convert from a path to an authorized URL. This is done in the auth_link method.
def link_for(path)
parts = Pathname(path).each_filename.to_a
bucket = parts[0]
path = parts[1..-1].join('/')
details = client.head_object(
{ bucket: bucket, key: path })
expires = 1.hour.from_now
extras = {
expires: expires,
file_name: File.basename(path),
file_size: details.content_length
}
download_url = signed_url(bucket,
path, expires.to_i)
[download_url, extras]
endThis was a bit more complicated as the Ceph gateway doesn’t support the lastest AWS signature format, so I had to add my own methods to generate the URL rather than using the AWS Client to do it for me. The main other piece of code is the details method which retrieves file size and creation date for the display.
So far it has been working well, although I still need to think about how to do the authentication. Currently the credentials are stored in the BrowseEverything configuration file. It would be good if the user could provide their own keys.
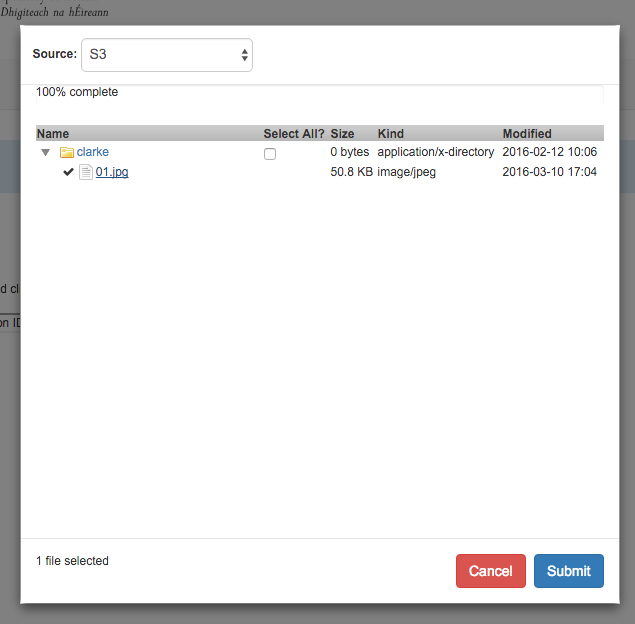
The full code is available in Github https://github.com/stkenny/browse-everything/tree/s3_provider